

En esta entrada del blog, compartiré un análisis de datos de misiones espaciales utilizando Pandas y Matplotlib.
A continuación, explicaré en detalle el proceso de limpieza, transformación y visualización de los datos, destacando la importancia de cada paso en la preparación de los datos para el análisis.
Implementación del Código
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
# Importamos las librerías necesarias para el análisis de datos y visualización
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Leemos el archivo CSV que contiene los datos de las misiones espaciales
df = pd.read_csv('C:/Users/mateo/Escritorio/python/projects/rocket_dataset/mission_launches.csv')
# Mostramos las primeras 10 filas del DataFrame para tener una idea general de los datos
df.head(10)
# Mostramos información general del DataFrame como el número de filas, columnas, tipos de datos y memoria utilizada
df.info()
# Eliminamos las columnas 'Unnamed: 0.1' y 'Unnamed: 0' que son irrelevantes para el análisis
df.drop(['Unnamed: 0.1','Unnamed: 0'], axis=1, inplace=True)
df.info()
# Convertimos la columna 'Date' a tipo datetime, manejando errores y estableciendo la zona horaria UTC
df['Date'] = pd.to_datetime(df['Date'], utc=True, errors='coerce')
df.info()
# Eliminamos las comas en la columna 'Price' y la convertimos a tipo float para poder realizar cálculos numéricos
df['Price'] = df['Price'].str.replace(',','').astype('float')
df.info()
# Rellenamos los valores nulos en la columna 'Price' con el valor promedio de la misma columna
df['Price'].fillna(df['Price'].mean(), inplace=True)
df.info()
# Eliminamos las filas donde la columna 'Date' es nula, ya que las fechas son cruciales para el análisis
df = df.dropna(subset='Date')
df.info()
# Extraemos el año de la columna 'Date' y lo almacenamos en una nueva columna llamada 'Year'
year = df['Date'].dt.year
df['Year'] = year
df.head(10)
# Extraemos el mes de la columna 'Date' y lo almacenamos en una nueva columna llamada 'Month'
month = df['Date'].dt.month
df['Month'] = month
df.head(10)
# Extraemos el país desde la columna 'Location', asumiendo que el país es el último elemento después de una coma
country = df['Location'].apply(lambda ctry: ctry.split(',')[-1].strip())
df['Country'] = country
df.head(10)
# Visualizamos la cantidad de misiones por país utilizando un gráfico de barras
y = df['Country'].value_counts().values
plt.bar(df['Country'].value_counts().index, y, color=plt.cm.viridis(y / max(y)))
plt.xticks(rotation = 45, ha = 'right')
plt.xlabel('Country')
plt.ylabel('Number of missions');
# Visualizamos la cantidad de misiones por organización utilizando un gráfico de barras
y = df['Organisation'].value_counts().values
plt.figure(figsize = (17,5))
plt.bar(df['Organisation'].value_counts().index, y, color=plt.cm.viridis(y / max(y)))
plt.xticks(rotation = 45, ha = 'right')
plt.xlabel('Organisation')
plt.ylabel('Number of missions');
# Visualizamos la cantidad de misiones por año utilizando un gráfico de barras
y = df.groupby('Year').size().values
plt.figure(figsize = (17,5))
plt.bar(df.groupby('Year').size().index, y, color=plt.cm.viridis(y / max(y)))
plt.xlabel('Year')
plt.ylabel('Number of missions');
# Visualizamos la cantidad de misiones por mes utilizando un gráfico de barras
y = df.groupby('Month').size().values
plt.bar(df.groupby('Month').size().index, y, color=plt.cm.viridis(y / max(y)))
plt.xlabel('Month')
plt.ylabel('Number of missions');
# Visualizamos el precio promedio de las misiones por año utilizando un gráfico de líneas
plt.figure(figsize = (12,5))
plt.plot(df.groupby('Year')['Price'].mean().index, df.groupby('Year')['Price'].mean().values, linestyle='-', marker='o')
plt.xlabel('Year')
plt.ylabel('Average Price');
# Visualizamos el estado de las misiones utilizando un gráfico de pastel
plt.figure(figsize = (8,8))
wedges, texts, autotexts = plt.pie(df['Mission_Status'].value_counts().values, labels=df['Mission_Status'].value_counts().index, autopct='%i%%', explode=[0,0.2,0.4,0.6], shadow=True, pctdistance=0.85)
# Ocultamos los textos para mejorar la legibilidad del gráfico
for text in texts:
text.set_visible(False)
# Añadimos una leyenda para el gráfico de pastel
plt.legend(title="Mission-Status", bbox_to_anchor=(1, 0, 0.5, 1))
# Centramos los textos que indican los porcentajes en el gráfico de pastel
for autotext in autotexts:
autotext.set_horizontalalignment('center')
# Creamos una tabla pivot que cuenta el número de misiones por año y estado de la misión
data_ms = df.pivot_table(index='Year', columns='Mission_Status', aggfunc='size', fill_value=0)
data_ms
# Visualizamos el número de misiones por año y estado de la misión utilizando un gráfico de líneas
plt.figure(figsize = (10,8))
plt.plot(data_ms["Success"].index,
data_ms["Success"],
color='g', label='Success')
plt.plot(data_ms["Failure"].index,
data_ms["Failure"],
color='r',
label='Failure')
plt.plot(data_ms["Partial Failure"].index,
data_ms["Partial Failure"],
color='y',
label='Partial Failure',)
plt.plot(data_ms["Prelaunch Failure"].index,
data_ms["Prelaunch Failure"],
color='black',
label='Prelaunch Failure')
plt.xlabel("Year")
plt.ylabel("Number of Launches")
plt.legend()
Explicación Detallada del Código
Importación de Bibliotecas
Para comenzar, importamos las bibliotecas necesarias para el análisis de datos y visualización.
1
2
3
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
Carga de Datos
1
df = pd.read_csv('C:/Users/mateo/Escritorio/python/projects/rocket_dataset/mission_launches.csv')
Leemos el archivo CSV que contiene los datos de las misiones espaciales.
1
2
df.head(10)
df.info()
Mostramos las primeras 10 filas del DataFrame para tener una idea general de los datos y la información general del DataFrame.
Revisamos la información general del DataFrame nos permite entender la estructura de los datos, los tipos de datos en cada columna y detectar posibles valores nulos.
Limpieza y Conversión de Datos
1
2
df.drop(['Unnamed: 0.1','Unnamed: 0'], axis=1, inplace=True)
df.info()
Eliminamos las columnas que no aportan valor al análisis. En este caso, las columnas 'Unnamed: 0.1' y 'Unnamed: 0'
1
2
df['Date'] = pd.to_datetime(df['Date'], utc=True, errors='coerce')
df.info()
Convertimos la columna Date al tipo datetime para facilitar la manipulación y análisis de datos.
1
2
df['Price'] = df['Price'].str.replace(',', '').astype('float')
df.info()
Los valores de Price están en formato string y contienen comas. Los convertimos a tipo float para poder realizar cálculos y análisis.
1
2
df['Price'].fillna(df['Price'].mean(), inplace=True)
df.info()
Rellenamos los valores nulos en la columna Price con el valor promedio de la columna para mantener la consistencia en los datos.
1
2
df = df.dropna(subset='Date')
df.info()
Eliminamos las filas donde la columna Date es nula, ya que las fechas son cruciales para nuestro análisis.
Creación de Nuevas Columnas
1
2
3
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df.head(10)
Creamos nuevas columnas Year y Month a partir de la columna Date para facilitar el análisis.
1
2
df['Country'] = df['Location'].apply(lambda ctry: ctry.split(',')[-1].strip())
df.head(10)
Extraemos el país de la columna Location para analizar las misiones por país. Utilizamos una función lambda para dividir el string y obtener el último elemento, que representa el país.
Visualización de Datos
- ¿De qué país se han lanzado más cohetes?
1
2
3
4
5
6
y = df['Country'].value_counts().values
plt.bar(df['Country'].value_counts().index, y, color=plt.cm.viridis(y / max(y)))
plt.xticks(rotation=45, ha='right')
plt.xlabel('Country')
plt.ylabel('Number of missions')
plt.show()
Visualizamos el número de misiones por país usando un gráfico de barras. Esto nos ayuda a entender qué países tienen más actividad en lanzamientos espaciales.
Salida:
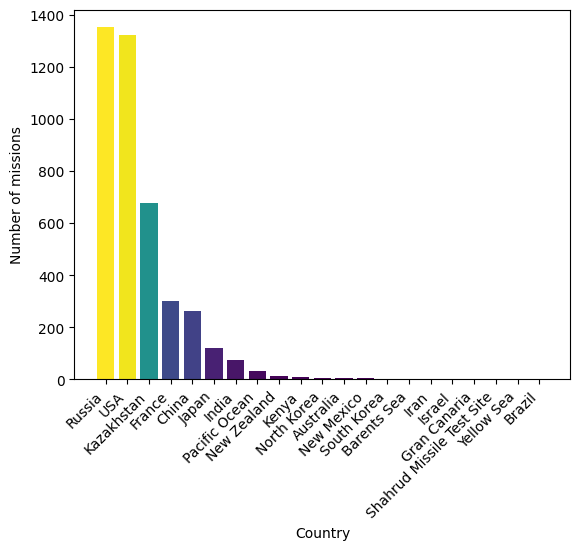
En esta gráfica podemos observar que hasta 2020 el país con más misiones espaciales lanzados es Rusia, seguido de cerca por Estados Unidos.
- ¿Qué organización ha lanzado más cohetes?
1
2
3
4
5
6
7
y = df['Organisation'].value_counts().values
plt.figure(figsize=(17,5))
plt.bar(df['Organisation'].value_counts().index, y, color=plt.cm.viridis(y / max(y)))
plt.xticks(rotation=45, ha='right')
plt.xlabel('Organisation')
plt.ylabel('Number of missions')
plt.show()
Visualizamos el número de misiones por organización con un gráfico de barras, lo que permite identificar las organizaciones más activas en lanzamientos espaciales.
Salida:
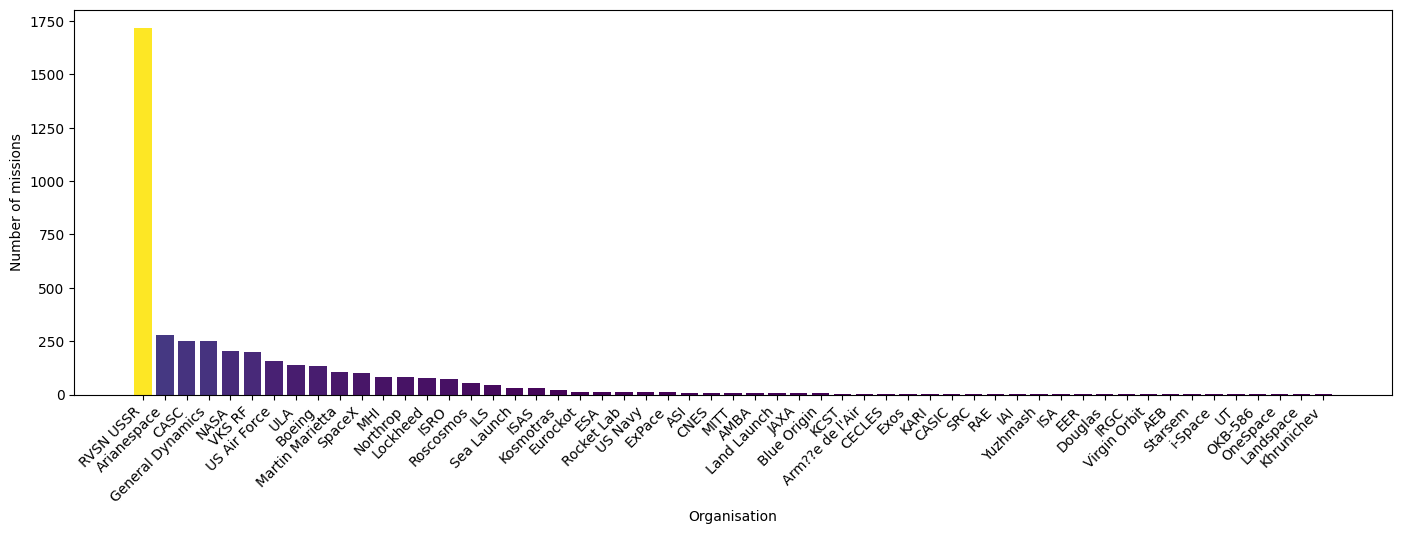
En esta gráfica de barras podemos obervar que la organización que más misiones ha realizado ha sido RVSN USSR, empresa espacial Rusa.
¿Cuántos lanzamientos se realizaron por año?
1
2
3
4
5
6
y = df.groupby('Year').size().values
plt.figure(figsize=(17,5))
plt.bar(df.groupby('Year').size().index, y, color=plt.cm.viridis(y / max(y)))
plt.xlabel('Year')
plt.ylabel('Number of missions')
plt.show()
Analizamos el número de misiones por año para identificar tendencias y patrones en la actividad de lanzamientos espaciales a lo largo del tiempo.
Salida:
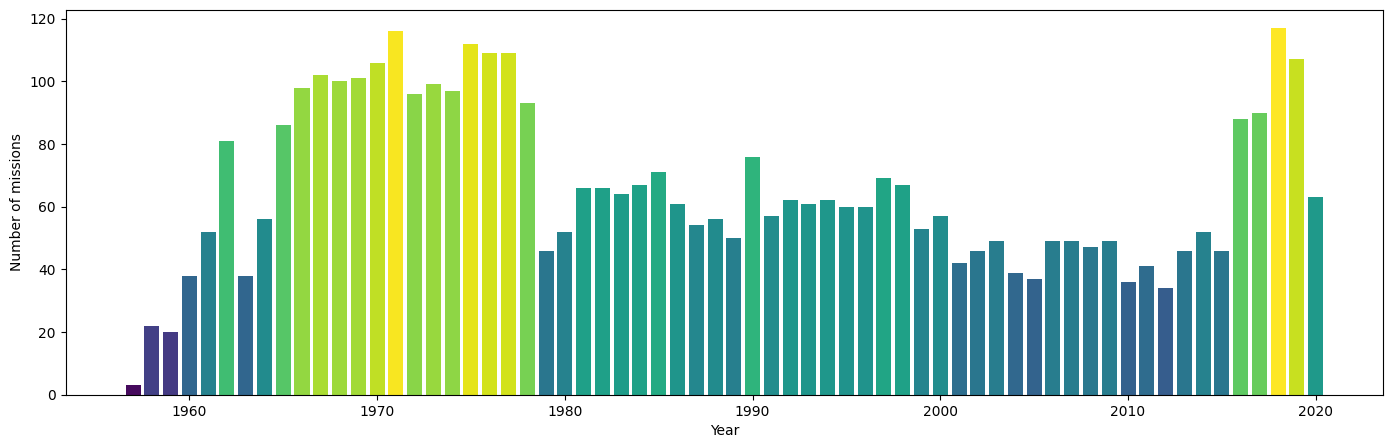
En esta gráfica podemos obervar que la los años con más actividad espacial son la década de 1970 y el año 2018.
¿Qué meses son los más populares para los lanzamientos?
1
2
3
4
5
y = df.groupby('Month').size().values
plt.bar(df.groupby('Month').size().index, y, color=plt.cm.viridis(y / max(y)))
plt.xlabel('Month')
plt.ylabel('Number of missions')
plt.show()
Evaluamos el número de misiones por mes para detectar estacionalidades en los lanzamientos espaciales.
Salida:
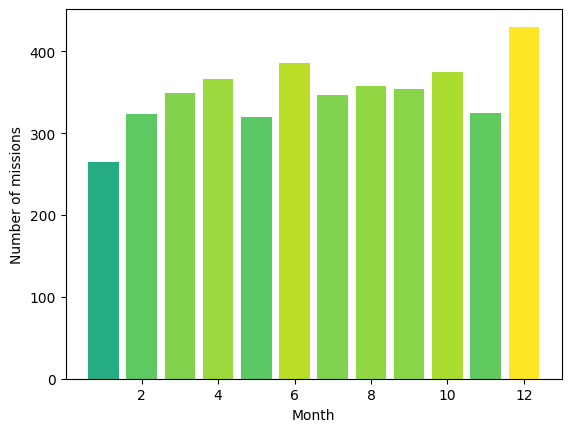
En esta gráfica podemos observar que el año preferido para el lanzamiento de misiones hasta el año 2020 ha sido Diciembre.
¿Cómo ha variado el costo de una misión espacial a lo largo del tiempo?
1
2
3
4
5
plt.figure(figsize=(12,5))
plt.plot(df.groupby('Year')['Price'].mean().index, df.groupby('Year')['Price'].mean().values, linestyle='-', marker='o')
plt.xlabel('Year')
plt.ylabel('Average Price')
plt.show()
Visualizamos el precio promedio de las misiones por año para observar cómo han cambiado los costos a lo largo del tiempo.
Salida:
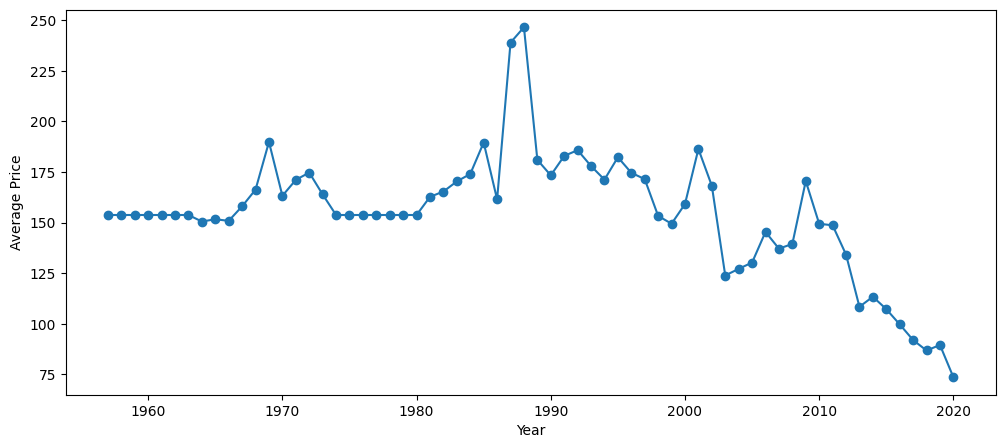
Salida:
En esta gráfica podemos observar que a partir de los 90s el precio de las misiones ha descendido drasticamente.
¿Se han vuelto más seguras las misiones espaciales o las posibilidades de fracaso se han mantenido sin cambios?
1
2
3
4
5
6
7
8
9
10
plt.figure(figsize=(8,8))
wedges, texts, autotexts = plt.pie(df['Mission_Status'].value_counts().values, labels=df['Mission_Status'].value_counts().index, autopct='%i%%', explode=[0,0.2,0.4,0.6], shadow=True, pctdistance=0.85)
for text in texts:
text.set_visible(False)
plt.legend(title="Mission-Status", bbox_to_anchor=(1, 0, 0.5, 1))
for autotext in autotexts:
autotext.set_horizontalalignment('center')
Usamos un gráfico de pastel para mostrar la proporción de diferentes estados de misiones, como éxitos, fracasos, fallos parciales y fallos en el lanzamiento.
Salida:
En este grafico de pastel podemos observar que hasta 2020 gran parte de los lanzamientos eran existosos (90%), pero aun así la cantidad de fallos en vuelo es muy alto (7%).
1
2
data_ms = df.pivot_table(index='Year', columns='Mission_Status', aggfunc='size', fill_value=0)
data_ms
Creamos una tabla pivote que cuenta el número de misiones por año y estado de la misión.
1
2
3
4
5
6
7
8
9
plt.figure(figsize=(10,8))
plt.plot(data_ms["Success"].index, data_ms["Success"], color='g', label='Success')
plt.plot(data_ms["Failure"].index, data_ms["Failure"], color='r', label='Failure')
plt.plot(data_ms["Partial Failure"].index, data_ms["Partial Failure"], color='y', label='Partial Failure')
plt.plot(data_ms["Prelaunch Failure"].index, data_ms["Prelaunch Failure"], color='black', label='Prelaunch Failure')
plt.xlabel("Year")
plt.ylabel("Number of Launches")
plt.legend()
plt.show()
Visualizamos el número de misiones por año y estado de la misión para entender mejor el desempeño y las tendencias a lo largo del tiempo.
Salida:
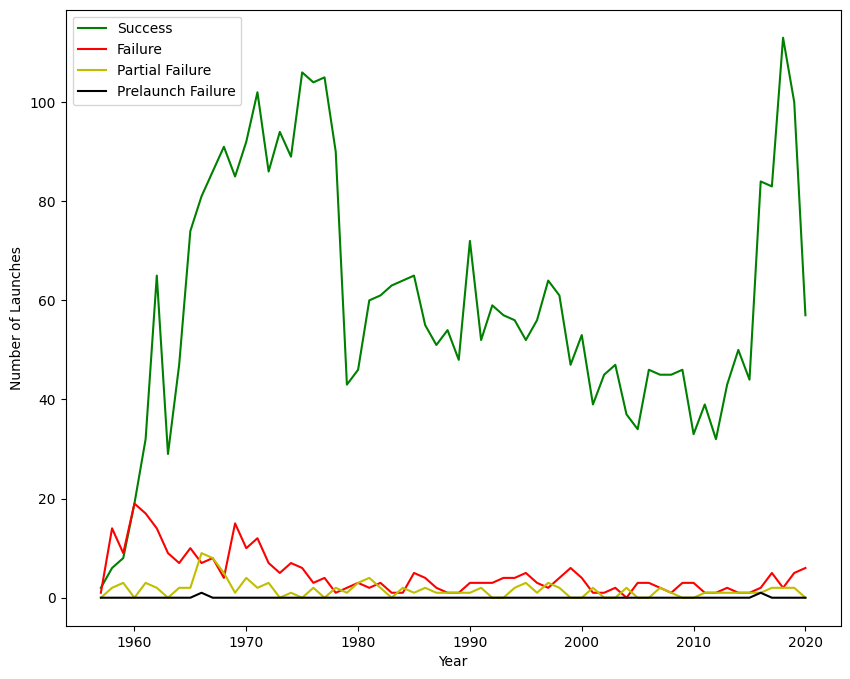
Conclusión
En este análisis, hemos limpiado, transformado y visualizado datos de misiones espaciales para obtener información valiosa sobre las tendencias y patrones en los lanzamientos de cohetes a lo largo del tiempo.
La preparación de los datos es crucial para garantizar la precisión y relevancia del análisis. Con datos limpios y bien estructurados, podemos crear visualizaciones significativas que nos permitan extraer conclusiones útiles.
Espero que os haya gustado y servido, cualquier comentario es de mucha ayuda. ¡Hasta la próxima!