
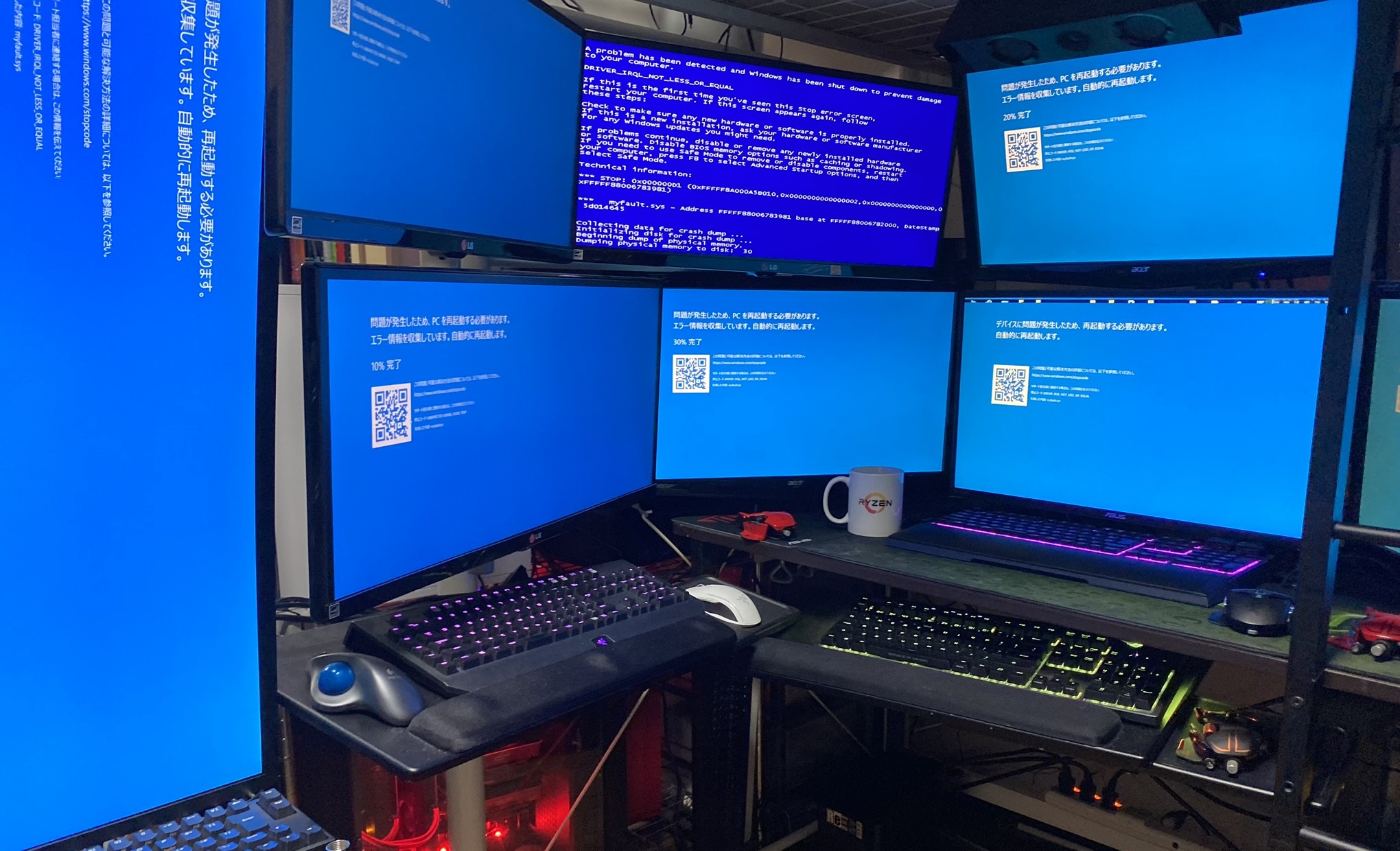
¡Imagina despertar un día y encontrar que tu ordenador muestra una pantalla azul gigante, y que este problema está ocurriendo en todo el mundo! Eso es exactamente lo que ha pasado el 19 de julio de 2024, cuando un error en una actualización de seguridad causó el mayor apagón cibernético de la historia. Desde hospitales hasta aeropuertos, casi todos los sistemas que usaban Windows se vieron afectados. ¡Sí, incluso muchos aviones tuvieron que aterrizar de emergencia!

Entornos empresariales, el 911, hospitales, controladores aéreos, organizaciones públicas, gobiernos, bancos, aeropuertos, tiendas, entre otros, se han visto afectados por este problema. Aunque mucha gente señala a Windows como la principal culpable de este apagón a nivel mundial, no es del todo correcto. Muchos expertos describen este acontecimiento como la mayor falla simultánea de IT en toda la historia.
Ayer, a las 06:32 UTC, se comenzaron a reportar errores con un archivo .sys dirigido a actualizar el contenido para los hosts de Windows. Pero, ¿qué empresa es la que se encarga de parte de la seguridad de estos sistemas y que, presuntamente, sería la mayor culpable de esta increíble situación?
CrowdStrike

¿Que es CrowdStrike y que relacion tiene con Microsoft?
CrowdStrike es una compañía de ciberseguridad especializada en la detección y prevención de amenazas.
Fundada en 2011 por George Kurtz, Dmitri Alperovitch y Gregg Marston, la empresa se destaca por su enfoque innovador en la protección de endpoints, como ordenadores y teléfonos móviles, mediante el uso de inteligencia artificial y análisis de big data.
CrowdStrike y Microsoft han colaborado en varias ocasiones para mejorar la seguridad cibernética. En 2017, CrowdStrike integró su plataforma Falcon con Microsoft Azure, permitiendo a los clientes de Azure utilizar sus capacidades avanzadas de detección y respuesta en la nube de Microsoft.
En 2019, la empresa se unió al programa Microsoft Intelligent Security Association (MISA), mejorando la interoperabilidad de sus soluciones con herramientas de seguridad de Microsoft, como Microsoft Defender y Azure Sentinel.
¿Qué es CrowdStrike Falcon?
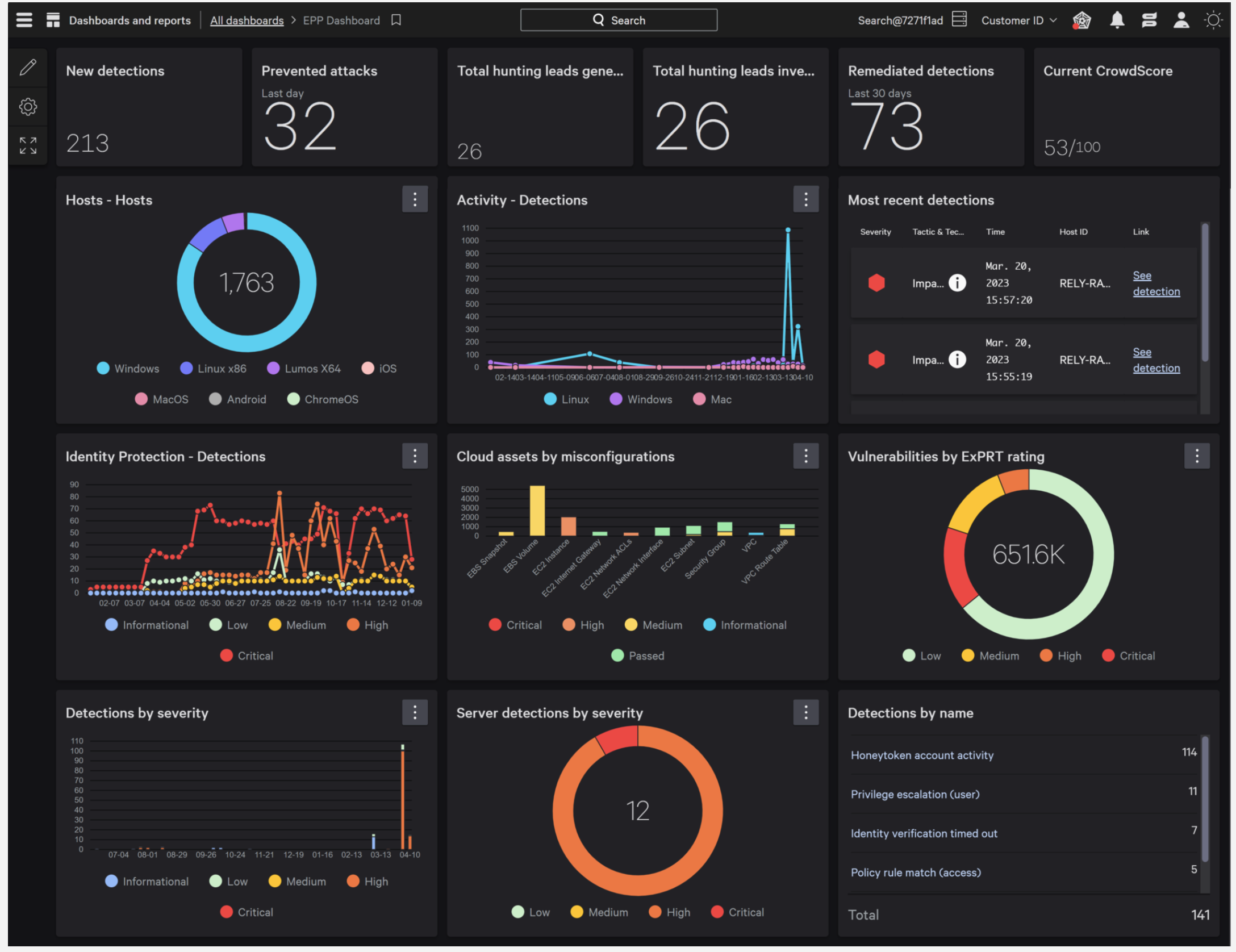
CrowdStrike Falcon Cloud Security es una solución avanzada de ciberseguridad diseñada para proteger los endpoints, como ordenadores, servidores y teléfonos móviles en tiempo real.
Desarrollada por CrowdStrike, esta plataforma está basada en la nube y se especializa en la detección, prevención y respuesta ante amenazas cibernéticas, ofreciendo una defensa integral contra una amplia gama de ataques.
¿Cúal ha sido el causante del fallo?
CrowdStrike Falcon requiere la instalación de una herramienta denominada “Falcon Sensor”. Este sensor es fundamental para el funcionamiento del software, ya que no solo instala servicios, sino también controladores que operan en modo Kernel. Estos controladores son esenciales para monitorizar la actividad del sistema a un nivel profundo, una práctica habitual en el software de seguridad para garantizar una protección exhaustiva.
A diferencia de las aplicaciones que funcionan en Modo Usuario, el sensor Falcon se ejecuta en modo Kernel. Esto implica que cualquier fallo en el sensor puede provocar problemas graves en el sistema. Mientras que una aplicación en Modo Usuario que falla generalmente puede reiniciarse sin mayores inconvenientes, un error en el modo Kernel puede causar un Kernel Panic, lo que resulta en la temida pantalla azul de la muerte en Windows.
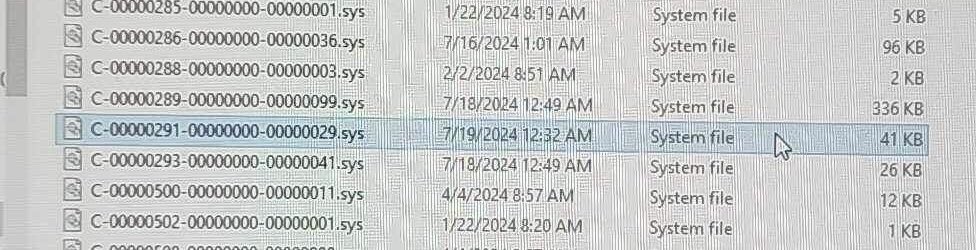
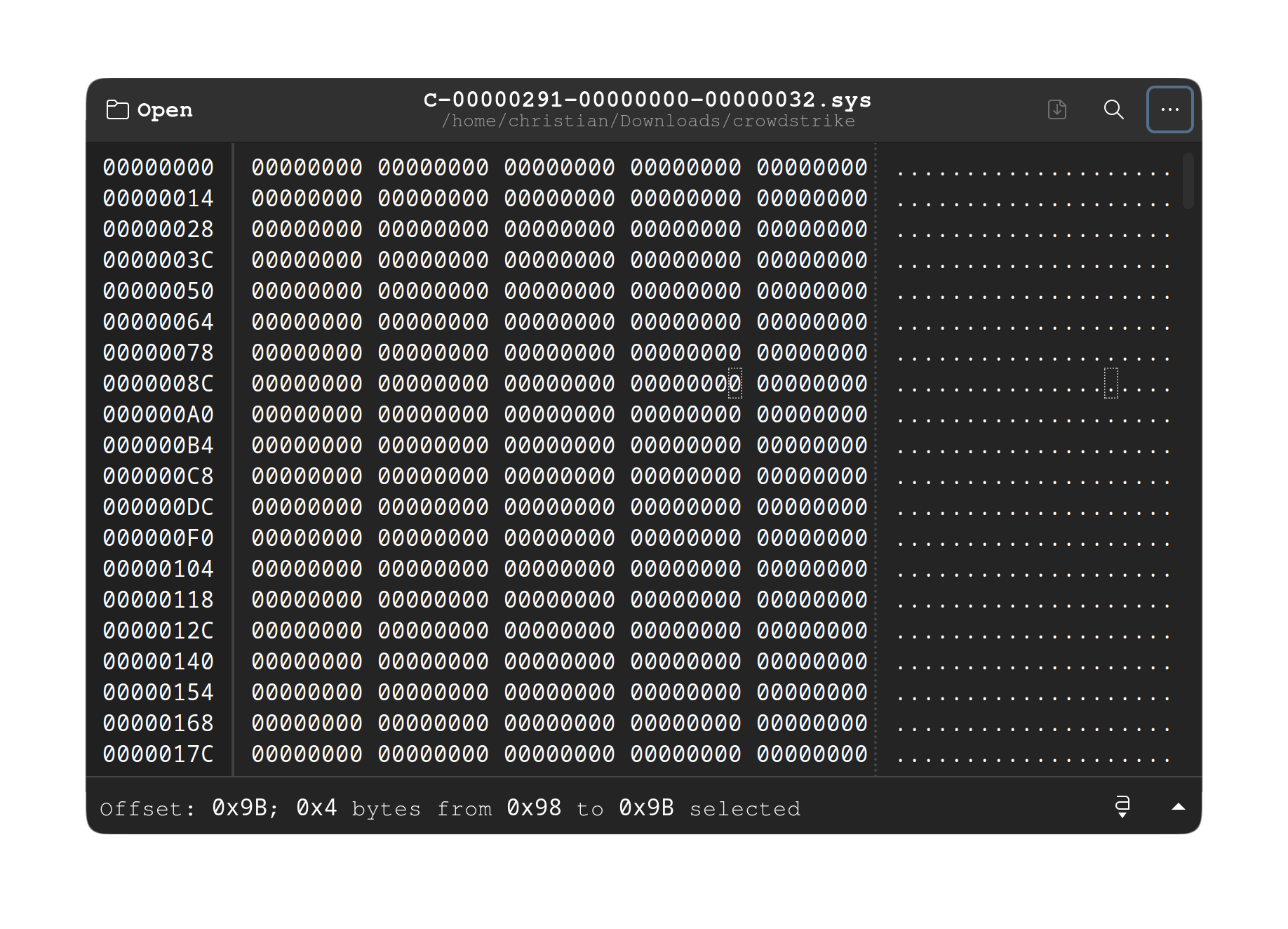
En este caso específico, el archivo del controlador defectuoso del sensor Falcon tiene un nombre que comienza con C-00000291 y termina en .sys. La actualización defectuosa de este controlador provocó un Kernel Panic, según el rastreo de la pila del pánico. El controlador parece haber hecho una lectura incorrecta en la dirección 0x9c, lo que desencadenó el fallo crítico.
Link Lectura Incorrecta en Memoria
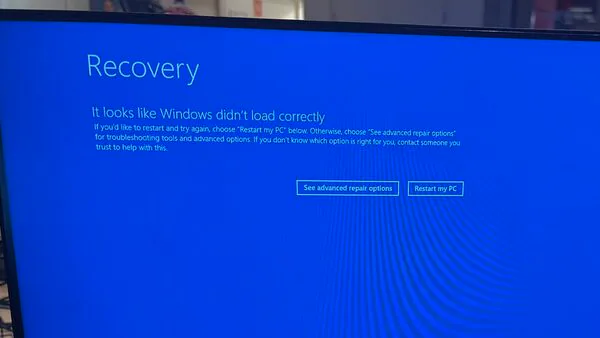
Mientras que algunos ordenadores pueden solucionar el problema mediante una actualización, muchos de los sistemas afectados necesitarán una reparación manual. La única solución es iniciar en Modo Seguro y eliminar el archivo C-00000291.sys (es decir, todos los archivos .sys que empiezan con C-00000291) ubicado en C:\Windows\System32\drivers\CrowdStrike.
Como los controladores de dispositivos se cargan durante el arranque del sistema, este problema puede llevar a Windows al modo de recuperación. Por lo tanto, la eliminación manual del archivo defectuoso es crucial para restaurar el funcionamiento normal del sistema.
Enlace al archivo por VirusTotal
Un usuario de Twitter (ahora X) llamado @Perpetualmaniac ha publicado una excelente explicación, con todo lujo de detalles, sobre el motivo por el cual la actualización de CrowdStrike provoca un pantallazo azul en los sistemas Windows. Según su análisis, el fallo proviene de un NULL pointer en memoria que ocurre en C++.
Hilo Explicación del Fallo de CrowdStrike
Muchos usuarios están investigando y han descubierto que el archivo C-00000291......032.sys contiene 41 KB de valores nulos o en blanco, probablemente debido a este NULL pointer en memoria pero curiosamente, el parche para solucionarlo, C-00000291......033.sys, es tan solo de 35 KB. Esto plantea una nueva pregunta: ¿fue un error del programador o del QA, o lo dejaron pasar?
El usuario de Perpetualmaniac sugiere que podría ser un movimiento estratégico para migrar los códigos más críticos de la empresa de C++ a Rust, aunque admite que esto es pura especulación y es probable que nunca lo sepamos con certeza. Sin embargo, la investigación es interesante y abre la puerta a más discusiones sobre prácticas de programación y calidad de software.
Impacto en el Mundo

Este fallo crítico, denominado por muchos como el mayor fallo IT en la historia, ha causado una serie de consecuencias devastadoras. Entre los impactos más notables, se encuentra el problema con los controladores aéreos en Estados Unidos, que obligó a todos los aviones en vuelo a aterrizar de inmediato. Además, los aviones que estaban en tierra no pudieron despegar, paralizando el tráfico aéreo en todo el país.
El alcance de esta interrupción ha sido tan significativo que se ha convertido en un ejemplo de cómo un fallo en el sistema de TI puede tener repercusiones a nivel global. Las operaciones de numerosos sectores han sido afectadas, y la magnitud del problema es evidente en la extensa cobertura mediática y las reacciones internacionales.
Para entender mejor el impacto visual de este incidente, te comparto un vídeo de FlightRadar que muestra la magnitud del caos en el tráfico aéreo. Puedes ver cómo el sistema de vuelos se ha visto gravemente afectado en tiempo real.
Además de los problemas mencionados, hemos sido testigos de algo que, sinceramente, nunca habíamos visto antes: billetes de avión escritos a mano. La magnitud del fallo y la interrupción en los sistemas digitales han llevado a una solución improvisada en el ámbito del transporte aéreo.
Ante la imposibilidad de emitir billetes electrónicos debido a la caída de los sistemas, algunos aeropuertos y compañías aéreas han recurrido a métodos tradicionales. Esto ha resultado en la emisión manual de billetes de avión, una práctica que parecía obsoleta en la era digital, pero que ha sido necesaria para mantener la operativa mínima en medio del caos.

Alejándonos del sector de la aviación y el transporte, también hemos visto problemas en lugares inesperados como la Fórmula 1. Durante el Gran Premio de Hungría, que se está disputando este fin de semana, el equipo Mercedes (del cual CrowdStrike es patrocinador) ha enfrentado serios inconvenientes debido a la interrupción del sistema.
El equipo no ha podido recibir información desde el muro de boxes, lo que ha afectado significativamente su capacidad para el desarrollo del Gran Premio.

Muchas tiendas, tanto grandes como pequeñas, se han visto obligadas a cerrar temporalmente debido a la incapacidad para realizar cobros a los clientes y gestionar las cuentas del local. La falla en el sistema ha tenido un impacto directo en la operativa diaria de estos establecimientos, que dependen en gran medida de sistemas digitales para realizar transacciones y mantener el control financiero.

Solución al problema
Además de los problemas inherentes al fallo, una complicación adicional es que la solución no puede aplicarse de manera automática. Como mencionamos anteriormente, cada sistema debe ser corregido individualmente siguiendo estos pasos:

Iniciar Windows en modo seguro o accede al entorno de recuperación de Windows.
Navegar hasta
C:\Windows\System32\drivers\CrowdStrike.Localizar el archivo cuyo nombre comienza con
C-00000291y termina en.sys, y eliminarlo.Reiniciar el sistema de manera normal.
Este proceso manual es necesario para solucionar el problema en cada máquina afectada, lo que puede ser laborioso, pero es esencial para restaurar el funcionamiento correcto del sistema.
Un usuario de la comunidad ha hecho un pequeño script que automatiza estos pasos, pero este habría que ejecutarlo equipo a equipo
Link Repositorio Github Automatización
Conclusión
El reciente fallo crítico causado por una actualización defectuosa del sistema Falcon de CrowdStrike subraya una lección fundamental sobre la importancia de las pruebas exhaustivas y la preparación para contingencias en el ámbito de la ciberseguridad y la gestión de sistemas. Este incidente ha demostrado cómo un archivo de apenas 41 KB puede desencadenar una serie de problemas a nivel global, paralizando operaciones en sectores críticos como:
- Aviación
- Transporte
- Hospitales
- Gobiernos
- Eventos deportivos
- …
La necesidad de pruebas rigurosas antes de desplegar actualizaciones en entornos de producción nunca ha sido tan evidente. Las pruebas deben realizarse en entornos controlados y simulados para identificar posibles conflictos y evitar que problemas críticos lleguen a afectar a usuarios finales y operaciones a gran escala.
La implementación de sistemas secundarios y planes de contingencia también es crucial. Contar con soluciones alternativas y procedimientos de recuperación puede mitigar el impacto de fallos imprevistos. La capacidad de restaurar sistemas y operaciones rápidamente es esencial para mantener la continuidad del negocio y reducir el tiempo de inactividad.
Este evento subraya la importancia de estar preparados para enfrentar problemas a nivel mundial. La coordinación entre proveedores de software, plataformas operativas y equipos de IT es fundamental para minimizar los riesgos y asegurar una respuesta efectiva ante incidentes críticos. La preparación para posibles fallos y la capacidad de respuesta rápida pueden marcar la diferencia en la resiliencia y estabilidad de las operaciones globales.
En resumen, la crisis actual no solo ilustra el impacto que puede tener un pequeño error en un archivo sobre sistemas a nivel mundial, sino que también resalta la necesidad imperiosa de pruebas rigurosas, preparación exhaustiva y estrategias de contingencia para enfrentar los desafíos en un entorno digital interconectado.
Fuentes
https://www.reddit.com/r/crowdstrike/
https://www.merca20.com/ceo-de-crowdstrike-mayor-caida-tech-de-la-historia/
https://www.ndtv.com/world-news/fix-deployed-ceo-of-firm-behind-global-microsoft-outage-6140433
https://twitter.com/ananayarora/status/1814276755420746213
Espero que os haya gustado leer el artículo tanto como a mi hacerlo. ¡Gracias por leer!